The standard roadmap teaches you to add AI to software. AI-native engineering is the reverse: you build software whose behavior comes from a model, and you treat the model's unpredictability as the central problem, not a detail to patch later.
That sounds like a slogan until you notice it reorders everything you'd learn. The usual path starts with Python, then data, then machine learning, then deep learning, and arrives at LLMs and deployment near the end.
It is a fine path for becoming an ML engineer. It is the wrong order for someone whose job is to make a probabilistic system behave in production. The skills that matter most show up last, if at all.
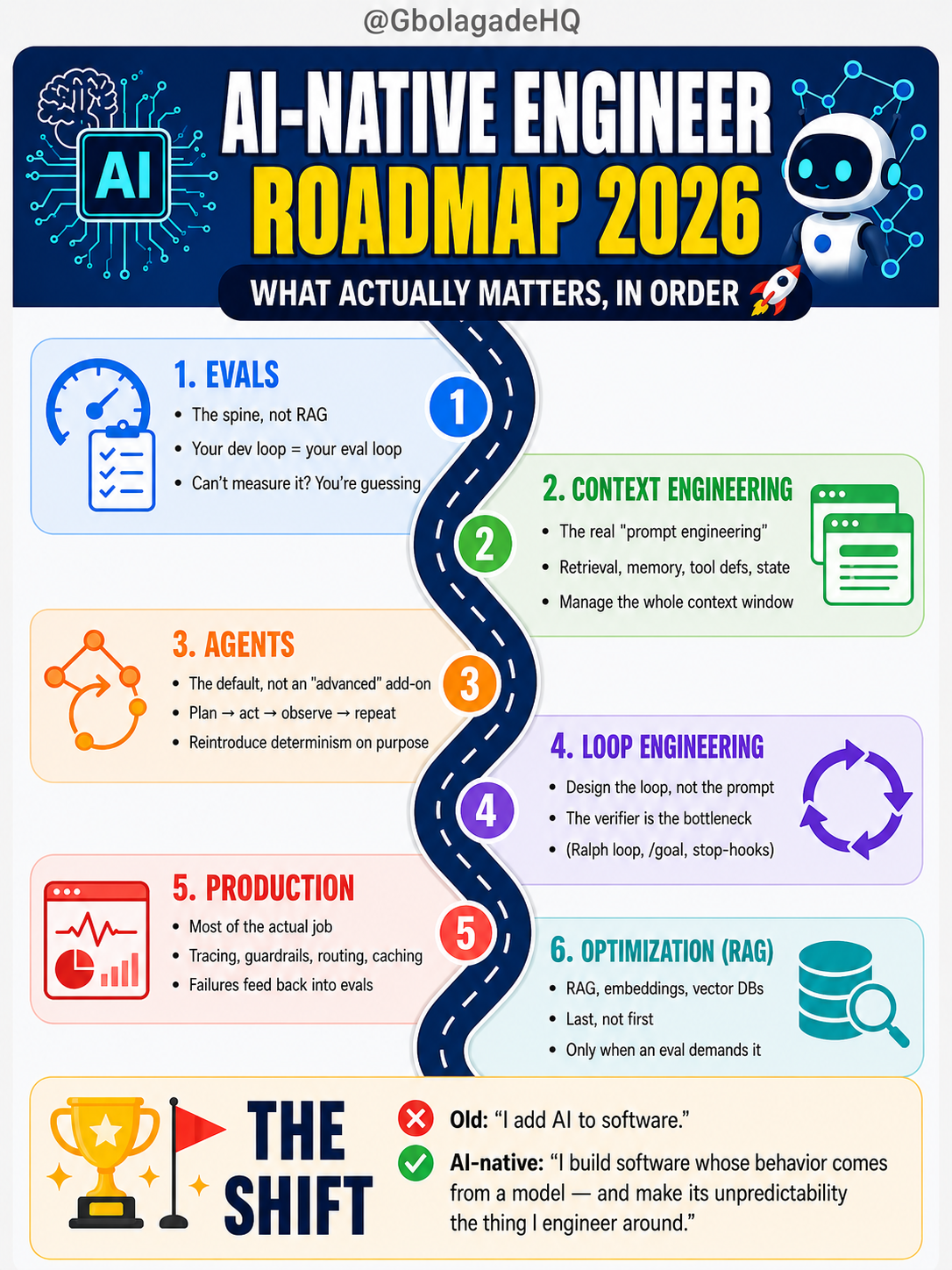
So here is the order I would actually learn it in, and why each step earns its place. The sequence is the argument.
Start by replacing one assumption
Normal software is correct or it is buggy. A model's output is neither. It is a distribution of outcomes, and your job is to push that distribution toward acceptable, not to eliminate the spread. You are managing variance, not removing it.
Every decision below follows from accepting that one fact. If you skip it, the rest reads as a pile of disconnected tools instead of a discipline.
1. Evaluation, not retrieval
This is the step the standard roadmap never reaches and the one I would put first. You cannot unit-test a stochastic system, because a single passing run proves nothing about the next one. So evaluation becomes the thing tests are in normal software: your development loop and your definition of done.
The methods are unremarkable once you commit to them. Programmatic checks where the output is structured. An LLM grading another model's output where the quality is subjective, calibrated against a set of human-labeled examples before you trust a word it says. Human review reserved for the high-stakes and the genuinely novel.
The discipline is mostly measurement. If you cannot measure whether a change helped, you are not engineering the system, you are guessing at it.
In my own work, the thing that drove error rates down to single digits was never a cleverer prompt. It was an eval harness with deterministic constraints, and guardrails validating the structured output before it ever reached a user.
2. Context engineering
This is the real version of "prompt engineering." Prompt wording is the smallest lever in the system. The real work is deciding what goes into the context window, in what order, and what gets removed: the retrieval, the memory, the tool definitions, the running state.
The model performs as well as the context you assemble for it, and no better. On longer-running tasks this stops being a nice-to-have and becomes the whole constraint, because the window is finite and recall degrades as it fills.
The fix is not a bigger context window. It is managing what stays in the one you have.
3. Agents as the default
Treat agents as the default, not an advanced topic. The standard roadmap files agents under "advanced," somewhere after reinforcement learning. In practice you reach for them early, and the loop itself is simple: plan, act, observe, repeat.
The engineering is not the loop. It is deciding which steps inside it should be ordinary, deterministic code instead of a model decision. Reintroducing determinism wherever you can is most of the reliability work.
I learned this building a production voice-and-chat assistant with a human in the loop. What made it reliable was never the model. It was a custom orchestration layer around the model: explicit state, durable memory, and tool-routing I could predict. I wrote about the control side of this in Loop Engineering, because it is where most agent projects quietly fall apart.
4. Loop engineering
This is the newest layer, and it has a name now. The model writes the prompts at this point. Your job moves up a level, to designing the loop the agent runs inside and the verifier that decides when it is finished.
That verifier is the bottleneck, not the model. It is the same problem evals solve, moved to runtime: you cannot trust a probabilistic system to report its own success, so something you wrote has to check the work and decide whether to continue.
5. Production reliability
This is where most of the job lives, and the roadmap barely mentions it. It is the part that separates a demo from something you can put in front of a customer and predict the bill for.
Tracing, so you can answer why a run failed instead of guessing. Guardrails, to catch bad output before a user sees it. Model routing, a cheap model for the easy cases and a frontier one for the hard. Caching.
Standardize the instrumentation on OpenTelemetry so you are not locked to one vendor, and close the loop by piping every production failure back into your eval set as a permanent regression test. Observability that does not feed improvement is just expensive logging.
I have built enough of this to open-source two pieces of it: a multi-provider LLM proxy with provider fallback and cost tracking, and an AI operations monitor for latency, cost, and failure trends. The deeper version of this argument is in Observability and Cost Control for AI Agents.
6. Optimization with RAG, last
Only now does RAG enter, as optimization, when an eval tells you it is needed. This is the part the standard roadmap puts at the center and I put last, on purpose. The reframe that matters: retrieval, not generation, is usually the bottleneck.
A naive pipeline retrieves the wrong passages and the model writes a confident, well-formed answer grounded in them. The reliable default is to retrieve broadly with hybrid search, rerank down to the few best passages, then generate.
On a large catalogue system, the biggest accuracy gain I got never came from a bigger model. It came from retrieval plus re-ranking, and from tuning the chunking to the domain. The same logic governs the wider context problem; I went into it in Enterprise Context Layers for Agents.
The shift
That is the whole sequence: evals, context, agents, loops, production, then optimization. Embeddings, vector databases, and RAG arrive at the end, because they are tools you reach for when measurement calls for them, not the place you start.
One honest caveat. "AI-native engineering" is not a settled term, and the vocabulary around it, loop engineering included, is young and still moving. This is one coherent definition of it: evals-first, agent-default, production-minded. Treat it as a frame to adapt, not a syllabus to memorize.
But the spirit holds regardless of what the field ends up calling it. Stop adding AI to software. Start building software whose behavior comes from a model, and make its unpredictability the thing you engineer around. The standard roadmap saves that realization for the end. It belongs at the start.